
Isten nyugtassa, Mester!

Jó eséllyel úgy vélné, túl sok minden nem változott, csak kevesebb helyen lehet sétálni, és több helyen biliárdozni.
Masszív képi adatbázis alapján tanulják meg algoritmusok, hogy egy jelenetben többet lássanak egy-egy tárgy színénél és formájánál. Értelmezniük kell a képet.
A Stanford Egyetem Mesterséges Intelligencia Laboratóriumában fejlesztett Vizuális Genom nevű képadatbázis rendeltetése, hogy számítógépek rajta keresztül tanuljanak meg képeket értelmezni, jöjjenek rá, mi történik a képen. Ha a képeket valamelyest megértik, akkor a való világból, a valóságból is többet felfognak.
A Vizuális Genom képeit gazdagabban felcímkézték, mint a labort vezető Fei-Fei Li által korábban fejlesztett ImageNet adatbázist. Az ImageNet 1 milliónál több, tartalmuk szerint felcímkézett kép gyűjteménye.
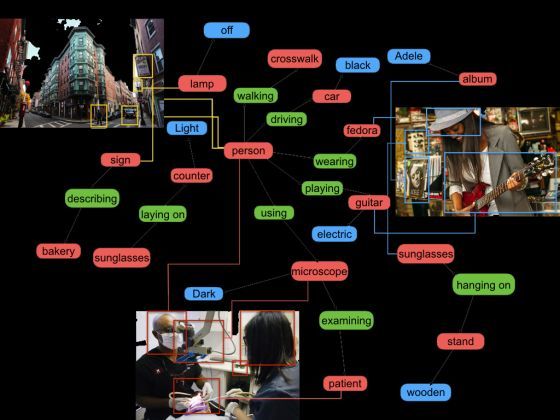
Li szerint a mesterségesintelligencia-kutatás szempontjából kulcsfontosságú, hogy a számítógépeknek megtanítsanak képeket elemezni és értelmezni. A Vizuális Genom képein, jelenetein tanuló algoritmusok elvileg lehetővé teszik, hogy például robotok vagy önvezető autók pontosan lássák a környező világot, és értelmet adjanak annak, amit látnak.
Ezekkel az algoritmusokkal a hatékonyabb kommunikáció és az is megtanítható számítógépeknek, hogy egyáltalán hogyan kommunikáljanak.
„A gépi látás legnehezebben megoldható kérdéseire összpontosítunk, hogy mi is köti össze valójában az érzékelést a gondolkodással. Nem csak pixeladatokról, színük, árnyalataik, formájuk és hasonlók értelmezéséről, hanem a háromdimenziós és szemantikus képi világ teljesebb megértéséről van szó” – magyarázza Li.
Jó eséllyel úgy vélné, túl sok minden nem változott, csak kevesebb helyen lehet sétálni, és több helyen biliárdozni.

Kell-e félnünk a mesterséges intelligenciától? Mi, emberek rendelkezünk-e felette? Elveheti-e a munkánkat? Milyen etikai kérdések merülnek fel az MI kapcsán? – szakértőt kérdeztünk.

„Nehéz lesz az eddigieknél durvábbakat mondani róla” – véli Bene Márton.

Az ukrajnai harcok és a gázai konfliktus az emberiség történetében az első olyan háború, amelyben a mesterséges intelligencia által irányított fegyverek jelentős szerepet kapnak. A hadviselésben valami új kezdődött, semmi sem lesz már úgy, mint régen. A gépek vezérelte harcra – ami, ha lehet, még az eddigieknél is könyörtelenebb – a tudósok hiába figyelmeztettek: a gyilkos robotoknak az ember nem tud ellenállni.

Európa lemarad a mesterséges intelligenciáért való versenyben, de a hagyományos tudás oktatására továbbra is szükség van – vallja Edoardo Rafiotta olasz jogászprofesszor.

A politológus szerint jelenleg több, párhuzamos síkon mozgó kihívással kell szembenéznie a Fidesznek, de ez a halmozás még a javára is válhat kormányzópártoknak.

Az amerikai hírszerzés szerint habár az orosz elnök megtehette volna, de nem volt érdekében, hogy éppen a választások előtt ölesse meg a nyugatbarát aktivistát.

Egy pince födéme nem bírta a 3,5 tonnás súlyt a VII. Kerületben.











